Computer Assignment 2: Frequency Distributions
Yuriy Davydenko
May 11 2020
Download the dataset for this assignment:
All the datasets we have used so far in a zip archive
DOWNLOAD ComputerAssignment_02.Rmd file USING THE LINK BELOW AND OPEN IT IN RStudio
Complete Assignment #2: Download link - Zip file - (Click “Save As”) (the file is ‘zipped’ and needs to be unzipped after downloading)
For those who prefer to work with RCloud, a project with the same materials can be accessed using the following link:
BEFORE STARTING, TYPE YOUR NAME INTO THE FIELD "author" IN THE HEADER OF THE MARKDOWN DOCUMENT AND REMOVE THIS COMMENT1. Load Libraries, Set Your Working Directory, & Load Data
Load Libraries:
library(dplyr) # for manipulating data
library(ggplot2) # for making graphs
library(knitr) # for nicer table formatting
library(summarytools) # for frequency distribution tablesSet your working directory, where the folder “Datasets” is located:
setwd(".") # for example: setwd("C:/Users/George/Dropbox/GSU/4041_Spring2020/R")Load the gss98 data set from the file “Datasets/gss98.RData” into R using load(file = "Datasets/gss98.RData") command. Before you run the command, make sure you have set the working directory correctly (folder “Datasets” should be in your working directory).
load(file = "Datasets/gss98.RData")2. Interpreting Frequency Distributions: RELIG
Generate a frequency distribution for RELIG using summarytools::freq(gss98$RELIG) command:
freq(gss98$RELIG)## Frequencies
##
## Freq % Valid % Valid Cum. % Total % Total Cum.
## ---------------- ------ --------- -------------- --------- --------------
## Catholic 250 25.30 25.30 25.00 25.00
## Jewish 20 2.02 27.33 2.00 27.00
## None 144 14.57 41.90 14.40 41.40
## Other 39 3.95 45.85 3.90 45.30
## Protestant 535 54.15 100.00 53.50 98.80
## <NA> 12 1.20 100.00
## Total 1000 100.00 100.00 100.00 100.00Generate a bar chart for RELIG using gss98 %>% ggplot() + geom_bar( aes(x = RELIG), fill = "darkred" ) (pick your own color for the chart):
gss98 %>% ggplot() + geom_bar( aes(x = RELIG), fill = "darkred" ) + labs(title = "Bar plot for RELIG")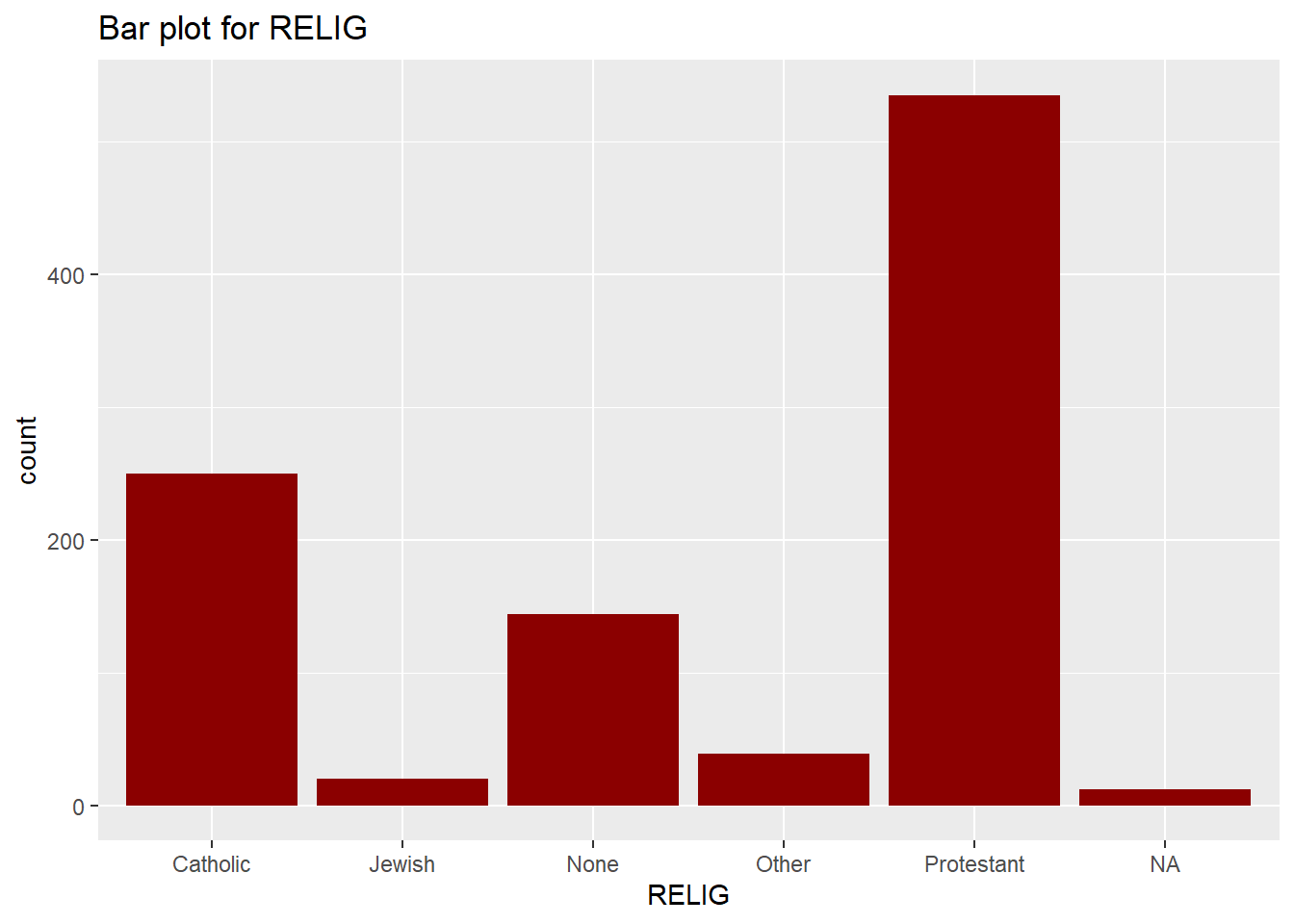
QUESTIONS:
A. How many people in this data set are Protestants? Catholics? Jews?
Replace this comment with your answers (make sure the text remains indented)B. What percentage of all respondents have no religion? What proportion have no religion? How were both numbers calculated?
Replace this comment with your answers (make sure the text remains indented)C. What advantage(s) and disadvantage(s) do you see to presenting a bar chart in place of a frequency table?
Replace this comment with your answers (make sure the text remains indented)3. Interpreting Frequency Distribution: FEPRESCH
Generate a frequency distribution for FEPRESCH using freq(DATASET_NAME$VARIABLE_NAME, round.digits = 1) command (hint: replace DATASET_NAME$VARIABLE_NAME with gss98$FEPRESCH as in the previous example):
# replace this commment with your code Generate a frequency graph for FEPRESCH (hint: use geom_bar() as in the previous example). Pick your own color and don’t forget the title:
# replace this commment with your code QUESTIONS:
A. Use the the codebook for the survey to find the exact question wording for the variable FEPRESCH. Copy it into your answer (You can cut and paste.)
Replace this comment with your answers (make sure the text remains indented)B. How many people in this data set strongly agree with this statement? What percentage of all respondents strongly agree with this statement?
Replace this comment with your answers (make sure the text remains indented)C. What percentage of the respondents who gave valid responses strongly agree with this statement? How was this number calculated? Why is this answer different from that in question 3B? Which percentage is most meaningful in this case - the “percent” or the “valid percent”? Why?
Replace this comment with your answers (make sure the text remains indented)D. How many missing cases are there?
Replace this comment with your answers (make sure the text remains indented)E. What does the 40.7 in the “Cum Percent” column mean? What is the absolute frequency who agreed or strongly agreed? What percentage disagreed or strongly disagreed? What is the absolute frequency who disagreed or strongly disagreed? (Show your work.)
Replace this comment with your answers (make sure the text remains indented)F. Interpret the bar plot for the variable FEPRESCH. Why did I ask you to plot a bar chart and not a histogram for this variable?
Replace this comment with your answers (make sure the text remains indented)4. Variable Types
QUESTION:
A. Are relig and fepresch nominal level, ordinal level, or interval level variables? How do you know? Write the names of at least two more of each type of variable in the data set.
Replace this comment with your answers (make sure the text remains indented)5. Comparisons
Have R produce frequency distributions for several variables having to do with confidence in U.S. institutions: CONCLERG, CONEDUC, CONFED, CONJUDGE, CONLEGIS, and CONPRESS.
# freq(gss98$CONCLERG)
# replace this commment with your command
# replace this commment with your command
# replace this commment with your command
# replace this commment with your command
# replace this commment with your commandQUESTIONS:
A. Use the codebook for the survey to find the exact question wording for each variable, Type your answer below:
[VAR: CONCLERG] --
[VAR: CONEDUC] --
[VAR: CONFED] --
[VAR: CONJUDGE] --
[VAR: CONLEGIS] --
[VAR: CONPRESS] -- B. The following commands extract second column from each frequency table above (% valid) to construct a table comparing confidence in the six institutions. Rank order the six institutions from the one that Americans have the most confidence in to the one they have the least confidence in. Does it make any difference whether you rank order the institutions by the “great confidence” or the “hardly any confidence” percentages?
data.frame( "CONCLERG" = freq(gss98$CONCLERG)[,2],
"CONEDUC" = freq(gss98$CONEDUC)[,2],
"CONFED" = freq(gss98$CONFED)[,2],
"CONJUDGE" = freq(gss98$CONJUDGE)[,2],
"CONLEGIS" = freq(gss98$CONLEGIS)[,2],
"CONPRESS" = freq(gss98$CONPRESS)[,2] ) %>% kable(digits = 1, caption = "Percent (%) Valid Responses")| CONCLERG | CONEDUC | CONFED | CONJUDGE | CONLEGIS | CONPRESS | |
|---|---|---|---|---|---|---|
| great confidence | 29.7 | 28.6 | 15.6 | 33.4 | 10.2 | 8.8 |
| some confidence | 50.8 | 56.4 | 48.9 | 53.6 | 58.7 | 51.1 |
| Hardly confidnce | 19.4 | 15.0 | 35.5 | 13.0 | 31.2 | 40.0 |
| NA | NA | NA | NA | NA | NA | |
| Total | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
Replace this comment with your answer (make sure the text remains indented)C. Write a short paragraph describing what you learn from the table. How much confidence do Americans seem to have in these institutions? Where do they place the greatest confidence? Use some percentages in your paragraph to make your points more explicit.
Replace this comment with your answer (make sure the text remains indented)
6. Histograms
Now, load a random sample of 500 observations from the 2000 U.S. Census Data from the file “Datasets/loan50.csv” into R using read.csv("Datasets/census.csv") coomand. Name the object census:
census <- read.csv("Datasets/census.csv")See the names and types of the variables in the dataset using names() and str() commands:
names(census)## [1] "census_year" "state_fips_code" "total_family_income"
## [4] "age" "sex" "race_general"
## [7] "marital_status" "total_personal_income"str(census)## 'data.frame': 500 obs. of 8 variables:
## $ census_year : int 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
## $ state_fips_code : Factor w/ 47 levels "Alabama","Arizona",..: 9 9 9 9 9 9 9 9 9 9 ...
## $ total_family_income : int 14550 22800 0 23000 48000 74000 23000 74000 60000 14600 ...
## $ age : int 44 20 20 6 55 43 60 47 54 58 ...
## $ sex : Factor w/ 2 levels "Female","Male": 2 1 2 1 2 1 1 1 1 1 ...
## $ race_general : Factor w/ 8 levels "American Indian or Alaska Native",..: 7 8 2 8 8 8 8 8 2 8 ...
## $ marital_status : Factor w/ 6 levels "Divorced","Married/spouse absent",..: 3 4 4 4 3 3 3 3 3 6 ...
## $ total_personal_income: int 0 13000 20000 NA 36000 27000 11800 48000 40000 14600 ...QUESTIONS:
Describe the following variables, their types (levels of measurement), and appropriate type of frequency distribution graph:
[VAR: marital_status] --
[VAR: sex] --
[VAR: age] --
[VAR: total_personal_income] -- Graph the frequency distribution for age:
census %>% ggplot(mapping = aes(x = age)) + geom_histogram( fill = "darkred" )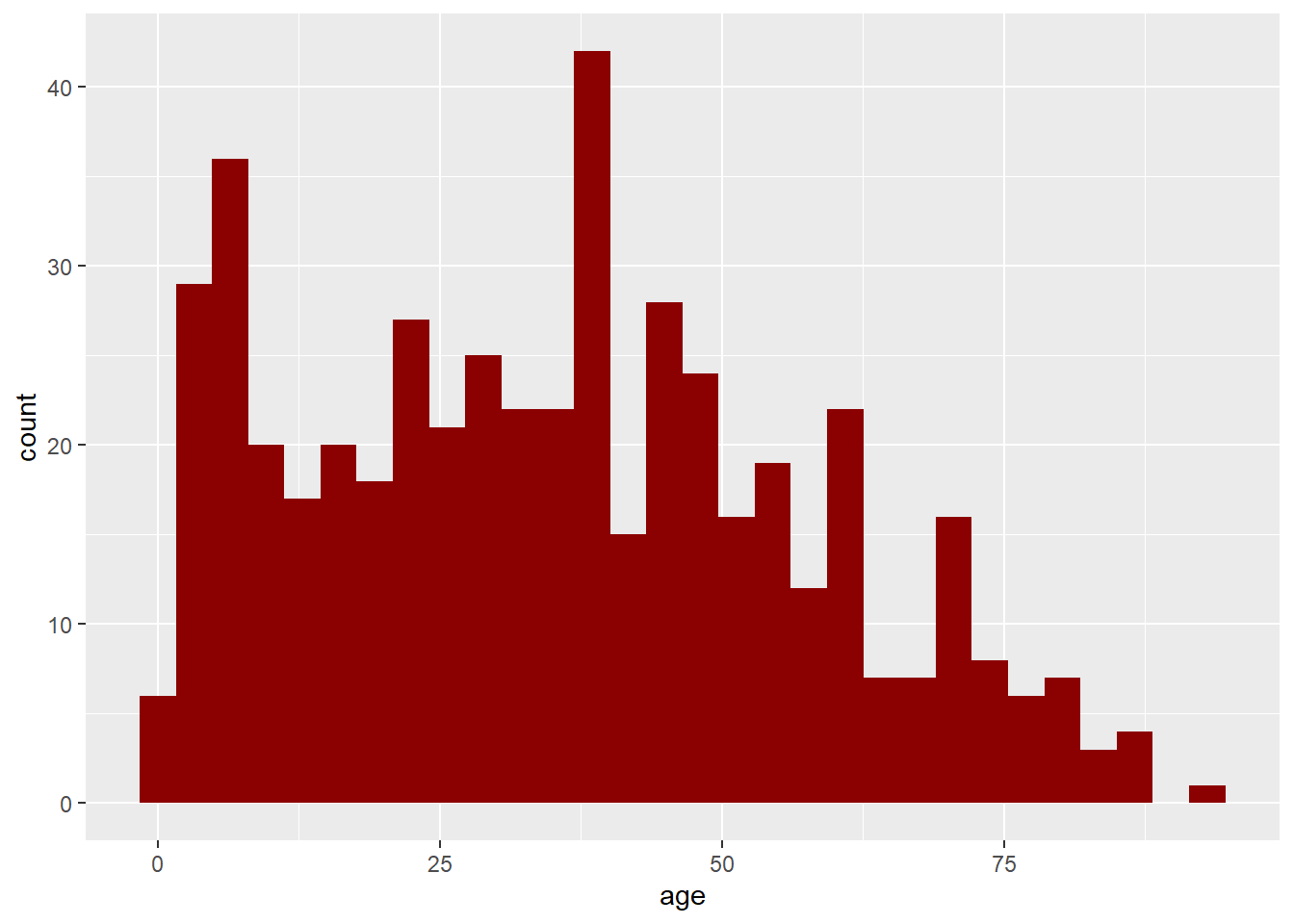
Describe the distribution:
Replace this comment with your answer (make sure the text remains indented)Graph the frequency distribution for total_personal_income using x = total_personal_income/1000 in ggplot command. Add a title and pick your own color:
#replace this note with your commandDescribe the distribution:
Replace this comment with your answer (make sure the text remains indented)7. Submission
Save your RMarkdown file, Knit an html report, and publish it on RPubs or save as a pdf file. Submit the link to the html or your pdf in the dropbox on iCollege.
Complete version of this assignment (omly graphs and tables to check your work) is here: